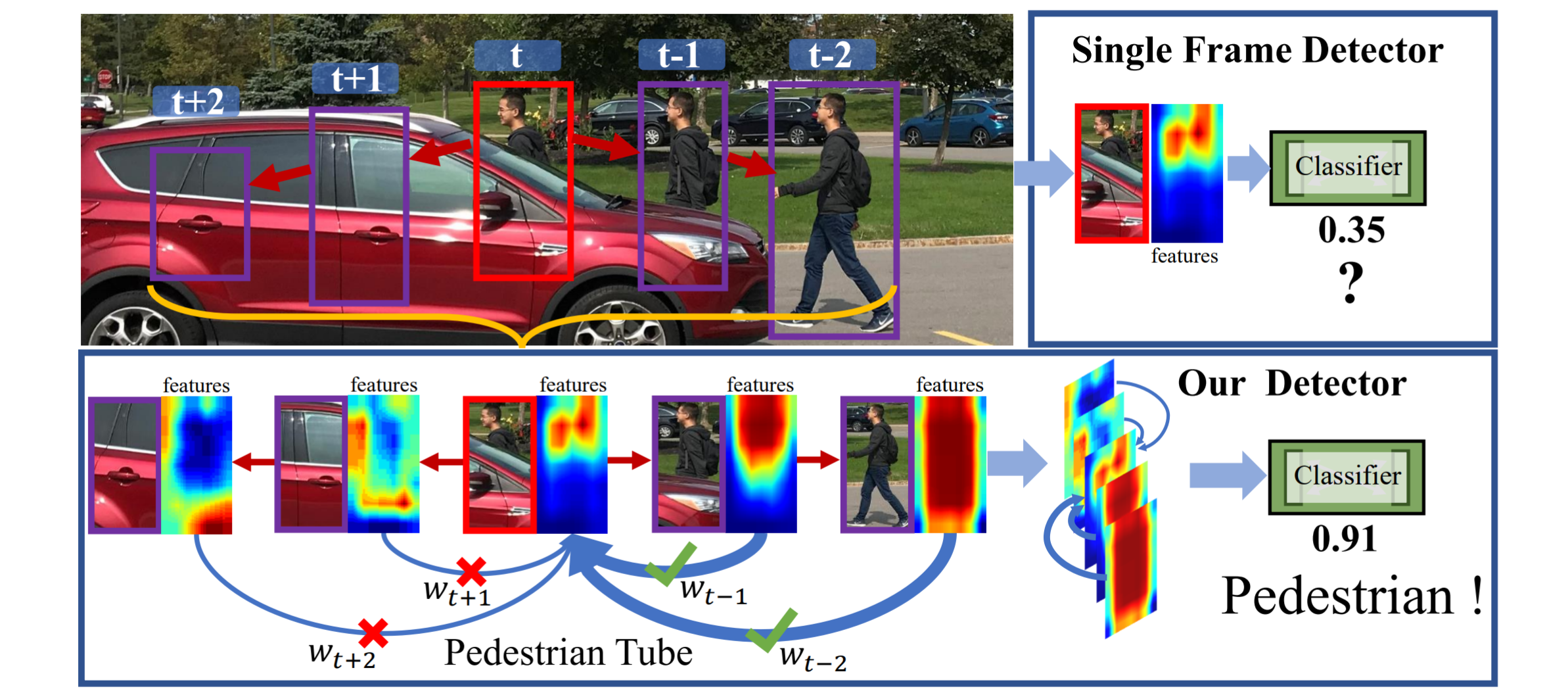
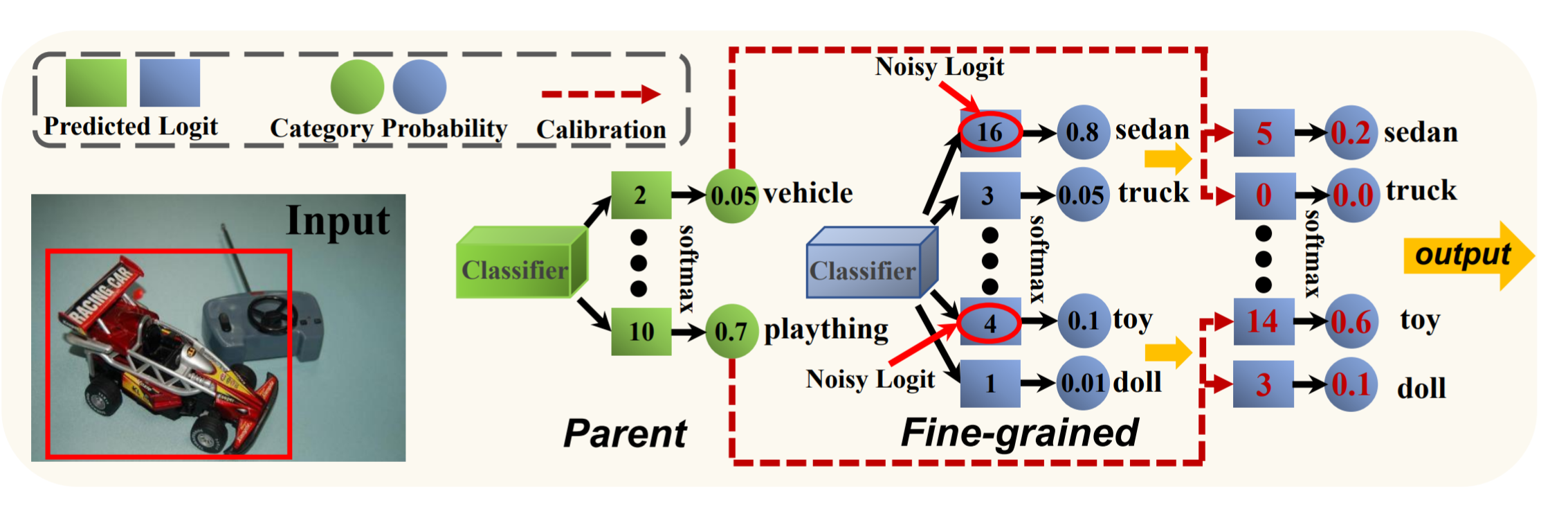
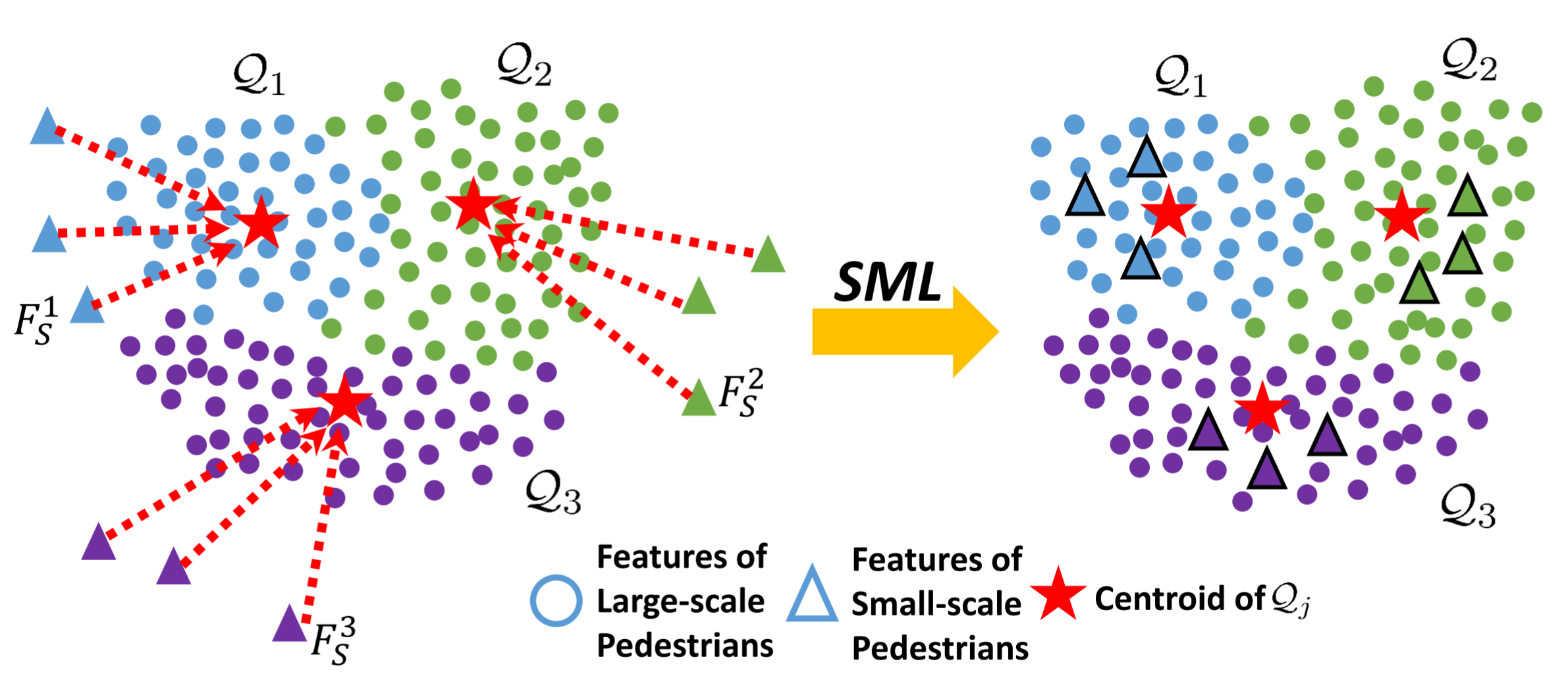
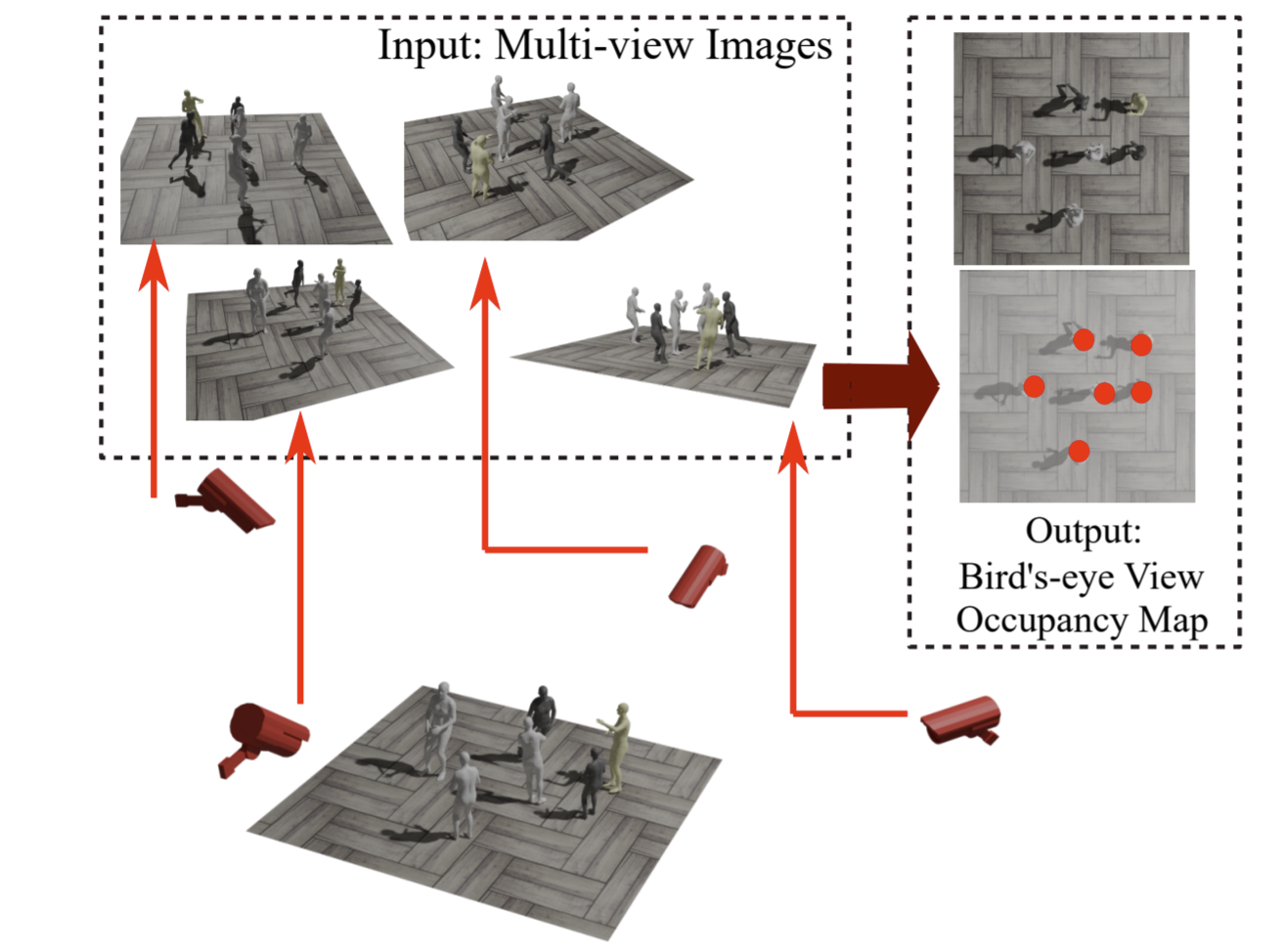
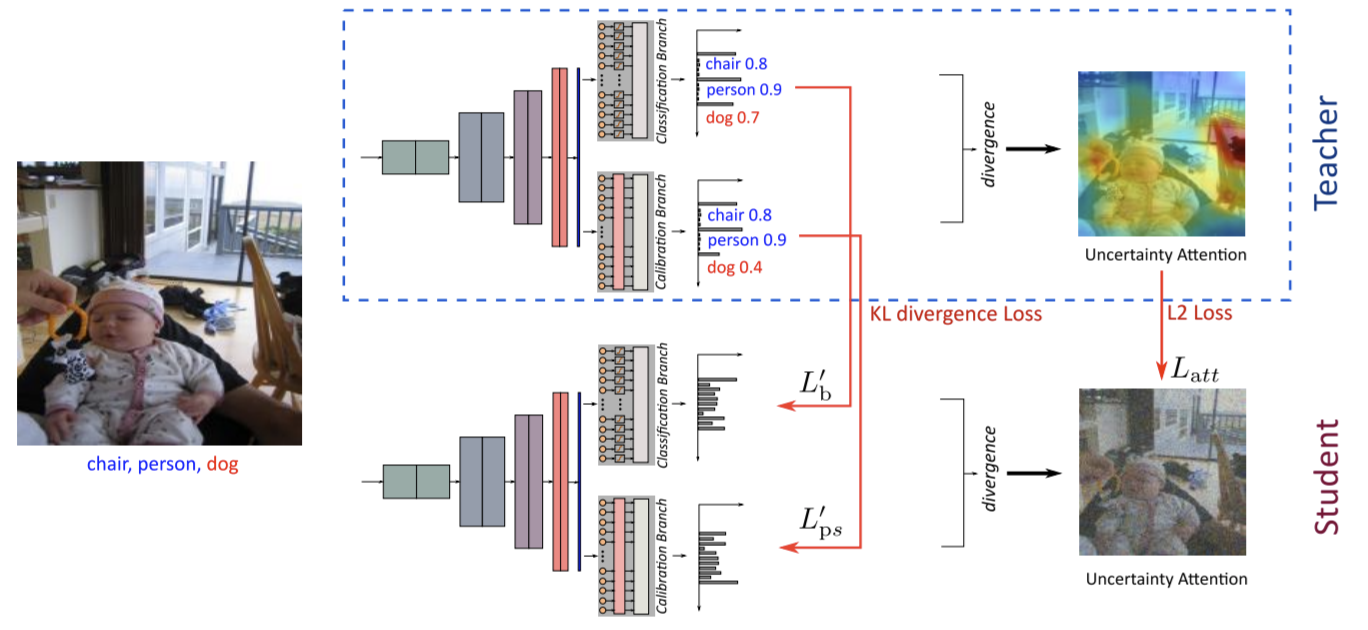
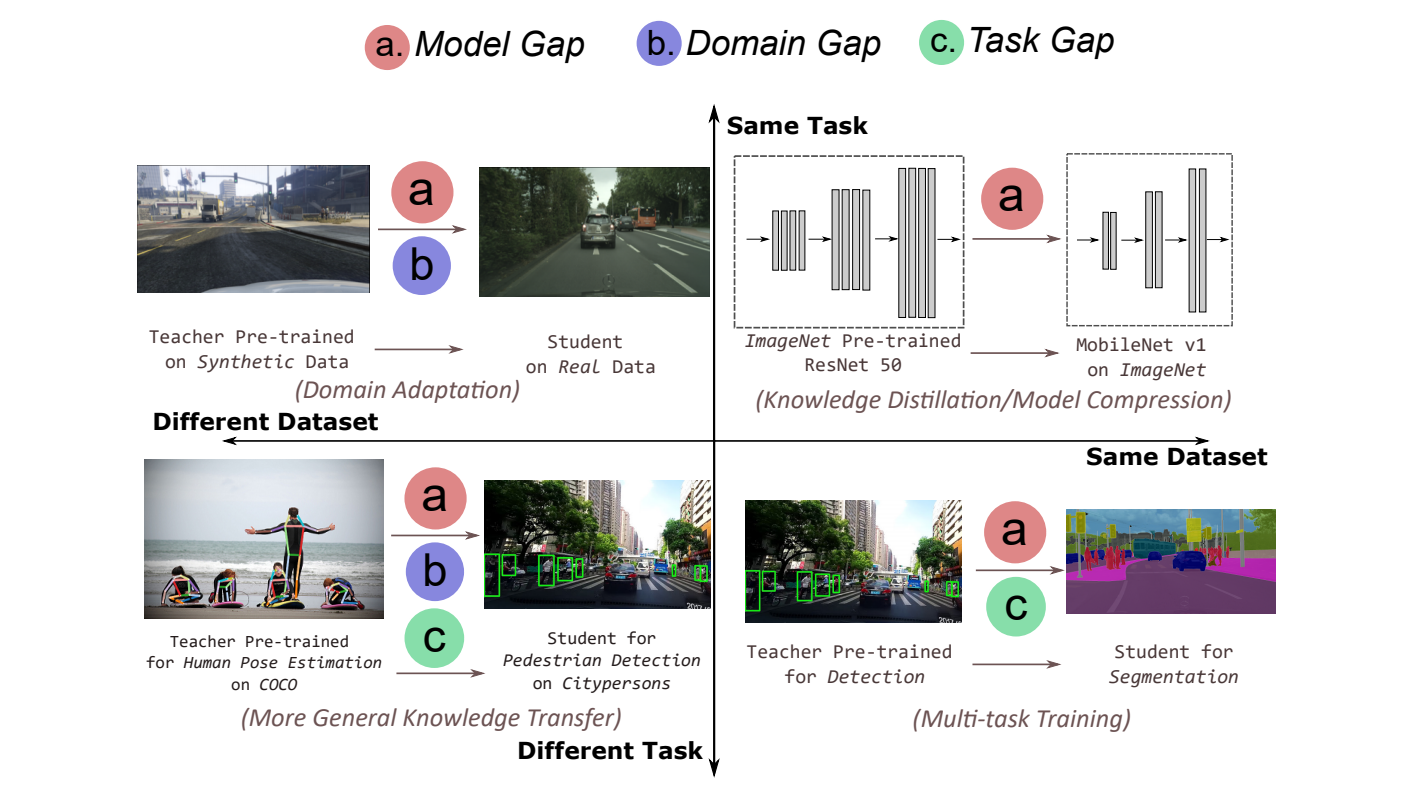
Jialian Wu (吴嘉濂)
Researcher @ AMD GenAI
Bellevue, WA
Email: Jialian.Wu at amd dot com
We're hiring research interns in LLM/Multimodal LLM/Image and Video Generation related topics. The aim is to publish papers at top conferences. Feel free to drop me an email with your CV if interested.